 |  |
 Markov Chains
Markov Chains

In a previous page, we studied the movement between the city and suburbs. Indeed, if I are S are the initial population of the inner city and the suburban area, and if we assume that every year 40% of the inner city population moves to the suburbs, while 30% of the suburb population moves to the inner part of the city, then after one year the populations are given by
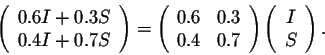
The matrix
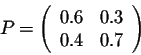
is very special. Indeed, the entries of each column vectors are positive and their sum is 1. Such vectors are called probability vectors. A matrix for which all the column vectors are probability vectors is called transition orstochastic matrix. Andrei Markov, a russian mathematician, was the first one to study these matrices. At the beginning of this century he developed the fundamentals of the Markov Chain theory.
A Markov chain is a process that consists of a finite number of states and some known probabilities pij, where pij is the probability of moving from state j to state i. In the example above, we have two states: living in the city and living in the suburbs. The number pij represents the probability of moving from state i to state j in one year. We may have more than two states. For example, political affiliation: Democrat, Republican, and Independent. For example, pij represents the probability of a son belonging to party i if his father belonged to party j.
Of particular interest is a probability vector p such that
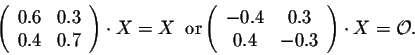
This system reduces to the equation -0.4 x + 0.3 y = 0. It is easy to see that, if we set
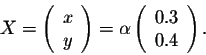
So the vector
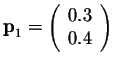 is a steady state vector of the matrix above. So if the populations of the city and the suburbs are given by the vector
is a steady state vector of the matrix above. So if the populations of the city and the suburbs are given by the vector Let us discuss another example on population dynamics.
Example: Age Distribution of Trees in a Forest
Trees in a forest are assumed in this simple model to fall into four age groups: b(k) denotes the number of baby trees in the forest (age group 0-15 years) at a given time period k; similarly y(k),m(k) and o(k) denote the number of young trees (16-30 years of age), middle-aged trees (age 31-45), and old trees (older than 45 years of age), respectively. The length of one time period is 15 years.
How does the age distribution change from one time period to the next? The model makes the following three assumptions:
- A certain percentage of trees in each age group dies.
- Surviving trees enter into the next age group; old trees remain old.
- Lost trees are replaced by baby trees.
Note that the total tree population does not change over time.
We obtain the following difference equations:
| b(k+1) | = | (1) | |
| y(k+1) | = | (1-db) b(k) | (2) |
| m(k+1) | = | (1-dy) y(k) | (3) |
| o(k+1) | = | (1-dm) m(k) + (1-do) o(k) | (4) |
Here 0 < db,dy,dm,do <1 denote the loss rates in each age group in percent.
Let
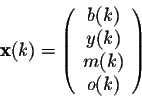
be the ``age distribution vector". Consider the matrix
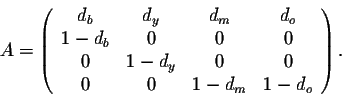
Then we have
Note that the matrix A is a stochastic matrix!
If, db=.1,dy=.2,dm=.3 and do=.4, then

After easy calculations, we find the steady state vector for the age distribution in the forest:
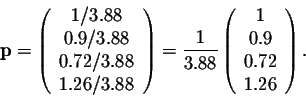
Assume a total tree population of 50,000 trees. Suppose the forest is newly planted, i.e.
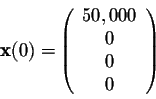
After 15 years, the age distribution in the forest is given by
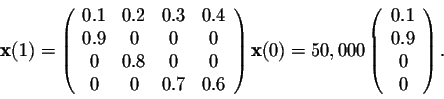
After 30 years, we have
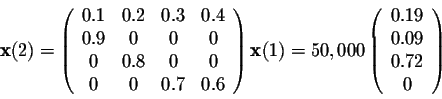
and after 45 years
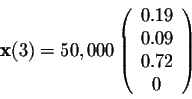
After 15n years, where
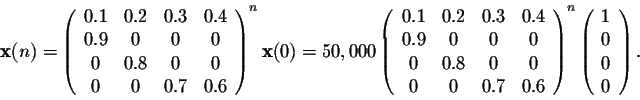
So the problem is to find the nth-power of the matrix A. We have seen that diagonalization technique may be helpful to solve this problem. Another problem deals with the long term behavior of the sequence x(n) when ngets large.
The calculations on the example above becomes tedious. Let us illustrate the problem on a small matrix.
Example. Consider the stochastic matrix
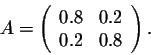
Note this is a symmetric matrix. The characteristic polynomial of A is
An eigenvector associated to 1 is
and an eigenvector associated to 0.6 is
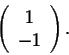
If we set
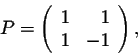
then we have
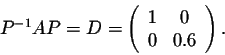
So, we have

When n gets large, the matrices An get closer to the matrix
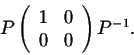
So the sequence of vectors defined by
will get closer to
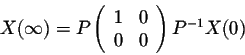
when n gets large. If
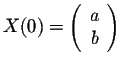 , then we have
, then we have 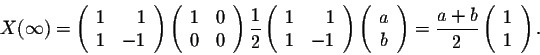
Note that the vector

This is not surprising. In fact there is a general result similar to the one above for any stochastic matrix.

Do you need more help? Please post your question on our S.O.S. Mathematics CyberBoard.

Author: M.A. Khamsi
 |
Contact us
Math Medics, LLC. - P.O. Box 12395 - El Paso TX 79913 - USA
800 users online during the last hour
No comments:
Post a Comment