DENORMALIZATION GUIDELINES
Craig S. Mullins, PLATINUM technology, inc. Normalization is the process of putting one fact in one appropriate place. This optimizes updates at the expense of retrievals. When a fact is stored in only one place, retrieving many different but related facts usually requires going to many different places. This tends to slow the retrieval process. Updating is quicker, however, because the fact you're updating exists in only one place. It is generally recognized that all relational database designs should be based on a normalized logical data model. With a normalized data model, one fact is stored in one place, related facts about a single entity are stored together, and every column of each entity refers non-transitively to only the unique identifier for that entity. Although an in-depth discussion of normalization is beyond the scope of this article, brief definitions of the first three normal forms follow: - In first normal form, all entities must have a unique identifier, or key, that can be composed of one or more attributes. In addition, all attributes must be atomic and non-repeating. (Atomic means that the attribute must not be composed of multiple attributes. For example, EMPNO should not be composed of social security number and last name because these are separate attributes.)
- In second normal form, all attributes that are not part of the key must depend on the entire key for that entity.
- In third normal form, all attributes that are not part of the key must not depend on any other non-key attributes.
Frequently, however, performance needs dictate very quick retrieval capability for data stored in relational databases. To accomplish this, sometimes the decision is made to denormalize the physical implementation. Denormalization is the process of putting one fact in numerous places. This speeds data retrieval at the expense of data modification. It is not the intention of this article to promote the concept of denormalization. Of course, a normalized set of relational tables is the optimal environment and should be implemented for whenever possible. Yet, in the real world, denormalization is sometimes necessary. Denormalization is not necessarily a bad decision if implemented wisely. You should always consider these issues before denormalizing: - can the system achieve acceptable performance without denormalizing?
- will the performance of the system after denormalizing still be unacceptable?
- will the system be less reliable due to denormalization?
If the answer to any of these questions is "yes," then you should avoid denormalization because any benefit that is accrued will not exceed the cost. If, after considering these issues, you decide to denormalize be sure to adhere to the general guidelines that follow. If enough DASD is available at your shop, create two sets of tables: one set fully normalized and another denormalized. Populate the denormalized versions by querying the data in the normalized tables and loading or inserting it into the denormalized tables. Your application can access the denormalized tables in a read-only fashion and achieve performance gains. It is imperative that a controlled and scheduled population function is maintained to keep the data in the denormalized and normalized tables synchronized. If DASD is not available for two sets of tables, then maintain the denormalized tables programmatically. Be sure to update each denormalized table representing the same entity at the same time, or alternately, to provide a rigorous schedule whereby tables will be synchronized. At any rate, all users should be informed of the implications of inconsistent data if it is deemed impossible to avoid unsynchronized data. When updating any column that is replicated in many different tables, always update it everywhere that it exists simultaneously, or as close to simultaneously as possible given the physical constraints of your environment. If the denormalized tables are ever out of sync with the normalized tables be sure to inform end-users that batch reports and on-line queries may not contain sound data; if at all possible, this should be avoided. Finally, be sure to design the application so that it can be easily converted from using denormalized tables to using normalized tables. The Reason for Denormalization Only one valid reason exists for denormalizing a relational design - to enhance performance. However, there are several indicators which will help to identify systems and tables which are potential denormalization candidates. These are: - Many critical queries and reports exist which rely upon data from more than one table. Often times these requests need to be processed in an on-line environment.
- Repeating groups exist which need to be processed in a group instead of individually.
- Many calculations need to be applied to one or many columns before queries can be successfully answered.
- Tables need to be accessed in different ways by different users during the same timeframe.
- Many large primary keys exist which are clumsy to query and consume a large amount of DASD when carried as foreign key columns in related tables.
- Certain columns are queried a large percentage of the time. Consider 60% or greater to be a cautionary number flagging denormalization as an option.
Be aware that each new RDBMS release usually brings enhanced performance and improved access options that may reduce the need for denormalization. However, most of the popular RDBMS products on occasion will require denormalized data structures. There are many different types of denormalized tables which can resolve the performance problems caused when accessing fully normalized data. The following topics will detail the different types and give advice on when to implement each of the denormalization types. Pre-Joined Tables If two or more tables need to be joined on a regular basis by an application, but the cost of the join is prohibitive, consider creating tables of pre-joined data. The pre-joined tables should: - contain no redundant columns (matching join criteria columns)
- contain only those columns absolutely necessary for the application to meet its processing needs
- be created periodically using SQL to join the normalized tables
The cost of the join will be incurred only once when the pre-joined tables are created. A pre-joined table can be queried very efficiently because every new query does not incur the overhead of the table join process. Report Tables Often times it is impossible to develop an end-user report using SQL or QMF alone. These types of reports require special formatting or data manipulation. If certain critical or highly visible reports of this nature are required to be viewed in an on-line environment, consider creating a table that represents the report. This table can then be queried using SQL, QMF, and/or another report facility. The report should be created using the appropriate mechanism (application program, 4GL, SQL, etc.) in a batch environment. It can then loaded into the report table in sequence. The report table should: - contain one column for every column of the report
- have a clustering index on the columns that provide the reporting sequence
- not subvert relational tenets (such as, 1NF and atomic data elements)
Report tables are ideal for carrying the results of outer joins or other complex SQL statements. If an outer join is executed and then loaded into a table, a simple SELECT statement can be used to retrieve the results of the outer join, instead of the complex UNION technique shown in Figure 1. Some RDBMS products support an explicit outer join function which can be used instead of the UNION depicted. However, depending on the implementation, the explicit outer join may be simpler or more complex than the UNION it replaces. Figure 1. Outer Join Technique Using UNION 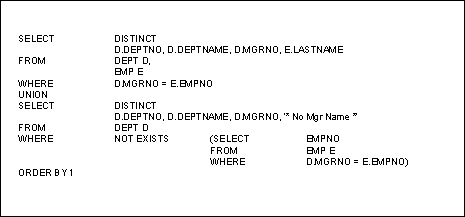
Mirror Tables If an application system is very active it may be necessary to split processing into two (or more) distinct components. This requires the creation of duplicate, or mirror tables. Consider an application system that has very heavy on-line traffic during the morning and early afternoon hours. This traffic consists of both querying and updating of data. Decision support processing is also performed on the same application tables during the afternoon. The production work in the afternoon always seems to disrupt the decision support processing causing frequent time outs and dead locks. This situation could be corrected by creating mirror tables. A foreground set of tables would exist for the production traffic and a background set of tables would exist for the decision support reporting. A mechanism to periodically migrate the foreground data to background tables must be established to keep the application data synchronized. One such mechanism could be a batch job executing UNLOAD and LOAD utilities. This should be done as often as necessary to sustain the effectiveness of the decision support processing. It is important to note that since the access needs of decision support are often considerably different than the access needs of the production environment, different data definition decisions such as indexing and clustering may be chosen for the mirror tables. Split Tables If separate pieces of one normalized table are accessed by different and distinct groups of users or applications then consider splitting the table into two (or more) denormalized tables; one for each distinct processing group. The original table can also be maintained if other applications exist that access the entire table. In this scenario the split tables should be handled as a special case of mirror table. If an additional table is not desired then a view joining the tables could be provided instead. 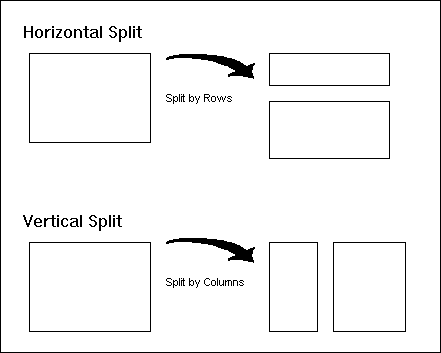
Tables can be split in one of two ways: vertically or horizontally. Refer to Figure 2. A vertical split cuts a table column-wise, such that one group of columns is placed into one new table and the remaining columns are placed in another new table. A horizontally split table is a row-wise split. To split a table horizontally, rows are classified into groups via key ranges. The rows from one key range are placed in one table, those from another key range are placed in a different table, and so on. Vertically split tables should be created by placing the primary key columns for the old, normalized table into both of the split tables. Designate one of the two, new tables as the parent table for the purposes of referential integrity unless the original table still exists. In this case, the original table should be the parent table in all referential constraints. If this is the case, and the split tables are read only, do not set up referential integrity (RI) for the split tables as they are being derived from a referentially intact source. RI would be redundant. When a vertical split is being done, always include one row per primary key in each split table. Do not eliminate rows from either of the two tables for any reason. If rows are eliminated the update process and any retrieval process that must access data from both tables will be unnecessarily complicated. When a horizontal split is being done, try to split the rows between the new tables to avoid duplicating any one row in each new table. This is done by splitting using the primary key such that discrete key ranges are placed in separate split tables. Simply stated, the operation of UNION ALL, when applied to the horizontally split tables, should not add more rows than contained in the original, un-split tables. Likewise, it should not contain fewer rows either. Combined Tables If tables exist with a one-to-one relationship consider combining them into a single combined table. Sometimes, even one-to-many relationships can be combined into a single table, but the data update process will be significantly complicated because of the increase in redundant data. For example, consider an application with two tables: DEPT (containing department data) and EMP (containing employee data). Combining the two tables into a large table named, for example, EMP_WITH_DEPT. This new table would contain all of the columns of both tables except for the redundant DEPTNO column (the join criteria). So, in addition to all of the employee information, all of the department information would also be contained on each employee row. This will result in many duplicate instances of the department data. Combined tables of this sort should be considered pre-joined tables and treated accordingly. Tables with one to one relationships should always be analyzed to determine if combination is useful. Redundant Data Sometimes one or more columns from one table are accessed whenever data from another table is accessed. If these columns are accessed frequently with tables other than those in which they were initially defined, consider carrying them in those other tables as redundant data. By carrying these additional columns, joins can be eliminated and the speed of data retrieval will be enhanced. This should only be attempted if the normal access is debilitating. Consider, once again, the DEPT and EMP tables. If most of the employee queries require the name of the employee's department then the department name column could be carried as redundant data in the EMP table. The column should not be removed from the DEPT table, though (causing additional update requirements if the department name changes). In all cases columns that can potentially be carried as redundant data should be characterized by the following attributes: - only a few columns are necessary to support the redundancy
- the columns should be stable, being updated only infrequently
- the columns should be used by either a large number of users or a few very important users
Repeating Groups When repeating groups are normalized they are implemented as distinct rows instead of distinct columns. This usually results in higher DASD usage and less efficient retrieval because there are more rows in the table and more rows need to be read in order to satisfy queries that access the repeating group. Sometimes, denormalizing the data by storing it in distinct columns can achieve significant performance gains. However, these gains come at the expense of flexibility. For example, consider an application that is storing repeating group information in the normalized table below: 
This table can store an infinite number of balances per customer, limited only by available storage and the storage limits of the RDBMS. If the decision were made to string the repeating group, BALANCE, out into columns instead of rows, a limit would need to be set for the number of balances to be carried in each row. An example of this after denormalization is shown below: 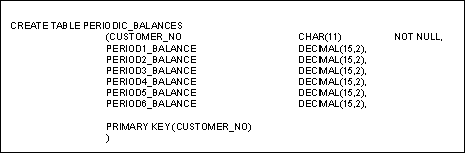
In this example, only six balances may be stored for any one customer. The number six is not important, but the concept that the number of values is limited is important. This reduces the flexibility of data storage and should be avoided unless performance needs dictate otherwise. Before deciding to implement repeating groups as columns instead of rows be sure that the following criteria are met: - the data is rarely or never aggregated, averaged, or compared within the row
- the data occurs in a statistically well-behaved pattern
- the data has a stable number of occurrences
- the data is usually accessed collectively
- the data has a predictable pattern of insertion and deletion
If any of the above criteria are not met, SQL SELECT statements may be difficult to code making the data less available due to inherently unsound data modeling practices. This should be avoided because, in general, data is denormalized only to make it more readily available. Derivable Data If the cost of deriving data using complicated formulae is prohibitive then consider storing the derived data in a column instead of calculating it. However, when the underlying values that comprise the calculated value change, it is imperative that the stored derived data also be changed otherwise inconsistent information could be reported. This will adversely impact the effectiveness and reliability of the database. Sometimes it is not possible to immediately update derived data elements when the columns upon which they rely change. This can occur when the tables containing the derived elements are off-line or being operated upon by a utility. In this situation, time the update of the derived data such that it occurs immediately when the table is made available for update. Under no circumstances should outdated derived data be made available for reporting and inquiry purposes. Hierarchies A hierarchy is a structure that is easy to support using a relational database such as DB2, but is difficult to retrieve information from efficiently. For this reason, applications which rely upon hierarchies very often contain denormalized tables to speed data retrieval. Two examples of these types of systems are the classic Bill of Materials application and a Departmental Reporting system. A Bill of Materials application typically records information about parts assemblies in which one part is composed of other parts. A Department Reporting system typically records the departmental structure of an organization indicating which departments report to which other departments. A very effective way to denormalize a hierarchy is to create what are called "speed" tables. Figure 3 depicts a department hierarchy for a given organization. The hierarchic tree is built such that the top most node is the entire corporation and each of the other nodes represents a department at various levels within the corporation. In our example department 123456 is the entire corporation. Departments 1234 and 56 report directly to 123456. Departments 12, 3, and 4 report directly to 1234 and indirectly to department 123456. And so on. The table shown under the tree in Figure 3 is the classic relational implementation of a hierarchy. There are two department columns, one for the parent and one for the child. This is an accurately normalized version of this hierarchy containing everything that is represented in the diagram. The complete hierarchy can be rebuilt with the proper data retrieval instructions. Figure 3. Classic Relational Implementation of a Department Hierarchy 
Even though the implementation effectively records the entire hierarchy, building a query to report all of the departments under any other given department can be time consuming to code and inefficient to process. Figure 4 shows a sample query that will return all of the departments that report to the corporate node 123456. However, this query can only be built if you know in advance the total number of possible levels the hierarchy can achieve. If there are n levels in the hierarchy then you will need n-1UNIONs. Figure 4. Querying the Departmental Hierarchy 
A "speed" table can be built such as the one in Figure 5. This table depicts the parent department and all of the departments under it regardless of the level. Contrast this to the previous table which only recorded immediate children for each parent. A "speed" table also commonly contains other pertinent information that is needed by the given application. Typical information includes the level within the hierarchy for the given node, whether or not the given node of the hierarchy is a detail node (at the bottom of the tree), and, if ordering within level is important, the sequence of the nodes at the given level. Figure 5. Speed Table Implementation of a Departmental Hierarchy 
After the "speed" table has been built, speedy queries can be written against this implementation of a hierarchy. Figure 6 shows various informative queries that would have been very inefficient to execute against the classical relational hierarchy. These queries work for any number of levels between the top and bottom of the hierarchy. A "speed" table is commonly built using a program written in COBOL or another high level language. SQL alone is usually either too inefficient to handle the creation of a "speed" table or impractical because the number of levels in the hierarchy is either unknown or constantly changing. Figure 6. Querying the Speed Table 
Types of Denormalization We have discussed nine different types of denormalization. The table below will summarize the types of denormalization that are available with a short description of when this type of denormalization is useful. 
Summary The decision to denormalize should never be made lightly because it involves a lot of administrative dedication. This dedication takes the form of documenting the denormalization decisions, ensuring valid data, scheduling of data migration, and keeping end users informed about the state of the tables. In addition, there is one more category of administrative overhead: periodic analysis. Whenever denormalized data exists for an application the data and environment should be periodically reviewed on an on-going basis. Hardware, software, and application requirements will evolve and change. This may alter the need for denormalization. To verify whether or not denormalization is still a valid decision ask the following questions: Have the processing requirements changed for the application such that the join criteria, timing of reports, and/or transaction throughput no longer require denormalized data? Did a new DBMS release change performance considerations? For example, did the introduction of a new join method undo the need for pre-joined tables? Did a new hardware release change performance considerations? For example, does the upgrade to a new high-end processor reduce the amount of CPU such that denormalization is no longer necessary? Or did the addition of memory enable faster data access enabling data to be physically normalized? In general, periodically test whether the extra cost related to processing with normalized tables justifies the benefit of denormalization. You should measure the following criteria: - I/O saved
- CPU saved
- complexity of update programming
- cost of returning to a normalized design
It is important to remember that denormalization was initially implemented for performance reasons. If the environment changes it is only reasonable to re-evaluate the denormalization decision. Also, it is possible that, given a changing hardware and software environment, denormalized tables may be causing performance degradation instead of performance gains. Simply stated, always monitor and periodically re-evaluate all denormalized applications. Craig S. Mullins is Vice President of Marketing and Operations for the database tools division of PLATINUM technology, inc. He has extensive experience in all facets of database systems development, including developing and teaching database and data modeling classes, systems analysis and design, database and system administration, and data analysis. Craig has worked with DB2 since V1 and has experience in multiple roles including programmer, DBA, instructor, and analyst. His experience spans industries having worked in manufacturing, banking, utilities, commercial software development, consulting and as a computer industry analyst for the Gartner Group. Additionally, Craig authored the popular DB2 Developer's Guide which provides over 1100 pages of tips, techniques, and guidelines to optimize DB2 for MVS. Craig is also a frequent contributor to computer industry publications having over five dozen articles published during the past few years. His articles have been published in magazines like Byte, DB2 Update, Database Programming & Design, DBMS, Data Management Review, Relational Database Journal, Enterprise Systems Journal, Mainframe Client/Server and others. Craig graduated cum laude with a degree in Computer Science and Economics from the University of Pittsburgh. [The Article Archive] The Data Administration Newsletter
Robert S. Seiner - Publisher and Editor - rseiner@tdan.com | 